udemy 강좌 내용[LangGraph- Develop LLM powered AI agents with LangGraph]의 일부를 정리한 내용입니다. 예제의 일부 내용을 수정하였습니다. 문제가 되면 삭제하겠습니다.
https://www.udemy.com/course/langgraph/learn/lecture/44106660#overview
Corrective Rag은 RAG에서 retrieval을 할 때 보다 답변 품질을 좋게 하는 고급 RAG 기술이다.
CRAG의 기본적인 개념은 간단하다. 기존의 RAG(Retrieval-Augmented Generation)와 유사하게 정보를 검색해 응답을 생성하지만, 사용자의 질문 의도를 보다 정확하게 반영하기 위해 "수정" 과정을 추가하는 접근 방식이다. 이를 통해 생성된 응답이 사용자 질문의 의도와 더 잘 맞도록 하는 것이 목적이다.
일반적인 RAG를 할 때 vector store에서 retrieve를 하고 검색된 내용을 가지고 LLM을 통해 generate를 하지만, CRAG은 retrieve한 문서가 적절한지를 판단하는 노드를 추가하는 것이다. 검색된 document가 question과 연관성이 있는지를 판단함으로써 불필요한 문서를 제거하는 역할을 수행할 수가 있다.

환경 구성
패키지 설치
pip install beautifulsoup4 langchain langgraph langchainhub langchain-community tavily-python langchain-chroma python-dotenv black위의 패키지를 설치를 하자.
.env 설정
OPENAI_API_KEY=sk-xxxx
TAVILY_API_KEY=tvly-xxx
LANGCHAIN_API_KEY=lsv2_xxx
LANGCHAIN_TRACING_V2=true
LANGCHAIN_PROJECT=CRAGindexing
[ingesting.py]
from dotenv import load_dotenv
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
load_dotenv()
urls = [
"https://namu.wiki/w/%EC%95%BC%EA%B5%AC/%EA%B2%BD%EA%B8%B0%20%EB%B0%A9%EC%8B%9D",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500, chunk_overlap=0, model_name="gpt-4o-mini"
)
doc_splits = text_splitter.split_documents(docs_list)
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="baseball-chroma",
embedding=OpenAIEmbeddings(),
persist_directory="./chroma",
)
retriever = Chroma(
collection_name="baseball-chroma",
embedding_function=OpenAIEmbeddings(),
persist_directory=chroma_directory,
).as_retriever()vector db는 chroma를 사용하고 namu wiki의 야구의 경기방식 문서를 테스트로 임베팅한다.
https://namu.wiki/w/%EC%95%BC%EA%B5%AC/%EA%B2%BD%EA%B8%B0%20%EB%B0%A9%EC%8B%9D
WebBaseLoader는 특정 URL을 호출하여 결과를 텍스트로 추출해준다. 문서 내에는 많은 HTML이 포함되어 있지만 HTML을 지우고 텍스트만 리턴한다.
chunk_size는 500 토큰으로 짜른다. from_tiktoken_encoder는 지정된 토큰 수로 짜르기 위해 사용된 함수이며 model_name을 사용할 모델 이름으로 지정해준다. 만일 지정하지 않으면 gpt-3로 사용되는 듯 하다. 모델별로 token 수가 달라질 수 있으니 참고하자.
이 파일을 실행하여 chroma db에 잘 등록이 되는지 확인하자. 파일을 열어서 확인해 보니 정상적으로 데이터가 들어간 것을 확인할 수 있다.

여기서 ingestion.py은 검색할 때 사용하는데 해당 파일을 동일하게 호출할 경우 여러 번 문서가 임베딩되는 문제가 있다. 그래서 이 파일에서 chroma로 임베딩 하는 부분을 주석처리하자.
#vectorstore = Chroma.from_documents(
# documents=doc_splits,
# collection_name="baseball-chroma",
# embedding=OpenAIEmbeddings(),
# persist_directory="./chroma",
# # persist_directory=chroma_directory,
# )State
[state.py]
from typing import List, TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
web_search: whether to add search
documents: list of documents
"""
question: str
generation: str
web_search: bool
documents: List[str]
여기서 graph 실행에 필요한 모든 state를 정의한다.
- question: 사용자의 질문이다.
- generation: LLM이 생성한 답변이다.
- web_search: 추가적인 결과가 필요한 경우 online 검색을 할지에 대한 boolean 값이다.
- documents: 질문에 대한 답변을 생성하는데 도움이 되는 documents를 저장한다. 문서를 vector에서 검색한 검색결과 문서가 된다.
Retriever Node
[retrieve.py]
from typing import Any, Dict
from graph.state import GraphState
from ingestion import retriever
def retrieve(state: GraphState) -> Dict[str, Any]:
print("---RETRIEVE---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}vector에서 semantic search를 하고 관련성 있는 문서를 검색한다. 리턴 값으로 documents 필드를 update 한다. 또한 질문(question)로 추가했다.
Document Grader Node
위에서 Retrieve Node에서 관련있는 문서를 검색했다. 그 문서가 실제로 질문과 관련이 있는지 판단해야 한다. 그 판단을 하기 위해 Retrieval grader chain을 만들어 LLM의 structed_output을 사용하여 문서가 관련이 있는지에 대한 정보를 가지고 있는 pydantic 객체로 변환한다. 만일 문서가 관련이 없으면 걸러내고 관련있는 문서만 유지한다. 만일 모든 문서가 사용자 질문과 관련이 없다면 web_search를 True로 표시할 것이고 웹 검색을 할 것이다.
[retrieval_grader.py]
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
llm = ChatOpenAI(temperature=0)
class GradeDocuments(BaseModel):
"""Binary score for relevance score on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
system = """You are a grade accessing relevance of a retrieved document to a user question. \n
If the document contains keywors(s) or semantic meaning related to the question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
binary_score는 문서가 질문과 관련 있는지에 대한 'yes' or 'no'를 가지는 필드이다. 여기서 description은 LLM이 그 내용을 읽고 판단하는데 중요한 역할을 하기 때문에 반드시 필요하다.
LLM을 호출하고 with_structured_output를 사용할 것이다. 여기서 GradeDocuments라는 pydantic model을 넘긴다. 내부적으로 function calling을 사용하며 모든 호출의 응답으로 pydantic 객체를 리턴한다.
그리고 system 프롬프트를 작성하고 grade_prompt를 생성한다.
다음으로 모든 문서를 평가하는 노드를 만들어보자.
[grade_documents.py]
from typing import Any, Dict
from graphs.chains.retrieval_grader import retrieval_grader
from graphs.state import GraphState
def grade_documents(state: GraphState) -> Dict[str, Any]:
"""
Determines whether the retrieved documents are relevant to the question
If any document is not relevant, we will set a flag to run web search
Args:
state (dict): The current graph state
Returns:
state (dict): Filtered out irrelevant documents and updated web_search state
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
filtered_docs = []
web_search = False
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade.lower() == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
if len(filtered_docs) == 0:
web_search = True
return {"documents": filtered_docs, "question": question, "web_search": web_search}노드는 state를 입력값으로 받는다. 이 노드에서는 검색된 documents를 받는다. 각각의 문서가 질문과 관련성이 있는지 판단하게 된다. 관련이 있으면 사용하고, 없다면 필터링 된다. 만일 관련있는 문서가 하나도 검색되지 않으면 웹검색을 사용하게 된다.
Tavily Web Search Node
여기서는 웹 검색 노드를 구현한다. Tavily를 사용하기 위해서는 API Key가 필요하다.
TAVILY 키가 없으면 새로 발급받자.
https://app.tavily.com/home
[web_search.py]
from typing import Any, Dict
from langchain.schema import Document
from langchain_community.tools.tavily_search import TavilySearchResults
from graph.state import GraphState
web_search_tool = TavilySearchResults(k=3)
def web_search(state: GraphState) -> Dict[str, Any]:
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
if documents is not None:
documents.append(web_results)
else:
documents = [web_results]
return {"documents": documents, "question": question}
Augmentation Generation Node
Generation Node는 마지막 노드이다. 관련성 있는 문서를 vector에서 검색하거나 웹 검색을 통해 검색결과를 받은 후에 이 노드를 실행한다. 즉, 관련성 있는 문서를 모두 찾은 다음 LLM으로 요청을 한다.
[generation.py]
from dotenv import load_dotenv
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI(temperature=0)
prompt = hub.pull("rlm/rag-prompt")
generation_chain = prompt | llm | StrOutputParser()rlm/rag-prompt은 RAG를 사용하는 표준 프롬프트로서 langchain team에서 만든 것이다.
다음으로 generation_chain을 실행하는 node를 생성하자.
[generate.py]
from typing import Any, Dict
from graph.chains.generation import generation_chain
from graph.state import GraphState
def generate(state: GraphState) -> Dict[str, Any]:
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
generation = generation_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}이 노드는 질문(question)을 받아 state의 documents를 가지고 generation_chain을 실행하는 역할을 한다.
Building & Running Graph
[consts.py]
RETRIEVE = "retrieve"
GRADE_DOCUMENTS = "grade_documents"
GENERATE = "generate"
WEBSEARCH = "websearch"[graph.py]
from dotenv import load_dotenv
from langgraph.graph import END, StateGraph
from graphs.consts import RETRIEVE, GRADE_DOCUMENTS, GENERATE, WEBSEARCH
from graphs.nodes import generate, grade_documents, retrieve, web_search
from graphs.state import GraphState
load_dotenv()
def decide_to_generate(state):
print("---ASSESS GRADED DOCUMENTS---")
if state["web_search"]:
print(
"---DECISION: NOT ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---"
)
return WEBSEARCH
else:
print("---DECISION: GENERATE---")
return GENERATE
workflow = StateGraph(GraphState)
workflow.add_node(RETRIEVE, retrieve)
workflow.add_node(GRADE_DOCUMENTS, grade_documents)
workflow.add_node(GENERATE, generate)
workflow.add_node(WEBSEARCH, web_search)
workflow.set_entry_point(RETRIEVE)
workflow.add_edge(RETRIEVE, GRADE_DOCUMENTS)
workflow.add_conditional_edges(
GRADE_DOCUMENTS,
decide_to_generate,
{
WEBSEARCH: WEBSEARCH,
GENERATE: GENERATE,
},
)
workflow.add_edge(WEBSEARCH, GENERATE)
workflow.add_edge(GENERATE, END)
app = workflow.compile()
app.get_graph().draw_mermaid_png(output_file_path="./graph.png")decide_to_generate를 정의하여 web_search 상태이면 WEBSEARCH 노드로 가게 하고 아니면 GENERATION 노드로 향하게 한다.
이제 StateGraph를 정의하자. 지금까지 만든 노드를 추가한다.
- retrieve
- grade_documents
- websearch
- generation
다음은 각 노드 간의 edge를 연결한다.
- retrieve -> grade_documents
- grade_document -> decide_to_generate(websearch, generate)
- websearch -> generate
그리고 compile 한다.
[main.py]
from dotenv import load_dotenv
load_dotenv()
from graphs.graph import app
if __name__ == "__main__":
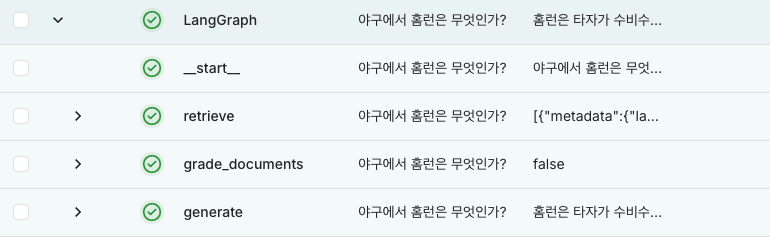
print(app.invoke(input={"question": "야구에서 홈런은 무엇인가?"}))graph를 실행하게 되면 아래와 같이 출력된다.
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
---GENERATE---
{'question': '야구에서 홈런은 무엇인가?', 'generation': '홈런은 타자가 수비수의 실책 없이 홈 베이스를 밟을 수 있게 공을 치는 것이다. 현대 야구에서는 공이 담장을 넘어가거나 수비수가 처리하지 못할 정도로 멀리 오랫동안 처리할 타구를 보내면 홈런으로 기록된다. 만루홈런을 치면 최대 4점을 득점할 수 있다.', 'web_search': False, 'documents': [Document(metadata={'language': 'ko', 'source': 'https://namu.wiki/w/%EC%95%BC%EA%B5%AC/%EA%B2%BD%EA%B8%B0%20%EB%B0%A9%EC%8B%9D', 'title': '야구/경기 방식 - 나무위키'}, page_content='살아서 올 세이프가 된 경우에는 안타가 아니라 야수선택으로 기록된다. 반대로 주자가 죽었더라도 주자가 한 개의 루를 지나서 추가 진루를 하려다가 죽은 경우(예를 들어 1사 1루 상황에서 우전 안타 - 주자가 2루를 지나 3루까지 가려다가 3루에서 죽은 경우)에는 타자에게는 안타를 인정한다.홈런(Home Run)수비수의 실책 없이 타자가 홈 베이스를 밟을 수 있게 공을 치는 것. 타자가 홈 베이스를 밟을 시간만큼 공을 치려면 수비가 못 잡도록 바운드가 되기 전에 아예 담장 밖으로 날려버리거나[25], 담장 안에 공이 떨어질 경우엔 수비수가 그동안 공을 처리하지 못할 정도로 멀리 오랫동안 처리할 타구를 보내야 한다. 현대 야구에서는 전자의 경우를 홈런으로 기록하고, 후자의 경우는 인사이드 파크 홈런으로 기록한다. 루상에 주자가 있으면 순서대로 진루하여 홈 플레이트를 밟으면 득점한다. 그렇기 때문에 만루홈런을[26] 치면 최대 4점을 득점할 수 있다. 다만 공의 착지점을 확인하기 애매할 때가 많은 만큼 이를 판정하기 위해 파울 라인과 페어 지역의 경계 지점에 파울 폴이 세워져 있는데, 일단은 당연히 이 안쪽으로 공이 들어가야 하고, 폴 위를 정확히 지나가거나 폴을 직접 맞추는 것도 홈런으로 인정된다. 또한 공이 펜스를 넘었다가 그물이나 관중에 의해 다시 공이 그라운드로 들어가는 경우에도 홈런으로 인정된다. 이를 확인하기 위해서 보통 단층 펜스 상단에 노란 줄을 긋고 줄을 넘어가면 홈런으로 인정하는 룰을 많이 쓴다.[27] 이중으로 펜스가 쳐진 경우는 예외. 획일적 구조로 지어진 한국과는 달리 미국은 구장마다 펜스의 생김새와 규정이 각각 달라서')]}4개의 retrieve된 문서 중에 1개만이 relevant로 평가되고 하나의 문서만을 통해 generate 노드에서 요청이 된다. 그리고 generate 노드에서 실행된 결과가 출력이 된다.
langgraph는 아래와 같이 실행이 된다.
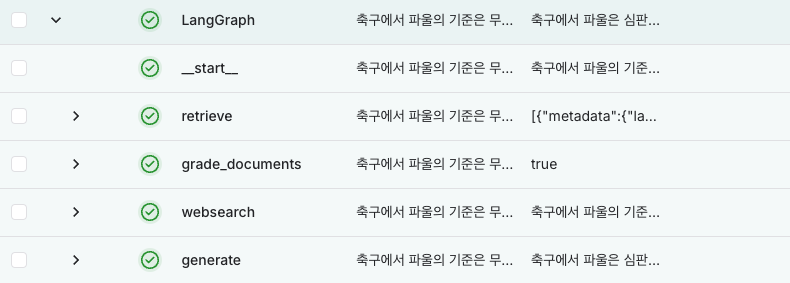
이 경우에는 websearch를 실행하지 않았다. websearch를 하는 하나의 예제를 만들어보자. 야구와 관련이 없는 질문을 던져보자.
if __name__ == "__main__":
print(app.invoke(input={"question": "축구에서 파울의 기준은 무엇인가?"}))이것을 실행해보면 아래와 같이 출력이 된다.
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: NOT ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---
---WEB SEARCH---
---GENERATE---
{'question': '축구에서 파울의 기준은 무엇인가?', 'generation': '축구에서 파울은 심판에 의해 판정되며, 주요 기준은 킥킹, 트립핑, 점핑 등의 행위입니다. 파울이 발생하면 파울의 종류와 위치에 따라 직접 프리킥 또는 간접 프리킥이 선언됩니다. 심판의 재량에 따라 파울의 기준이 상대적으로 덜 엄격할 수 있습니다.', 'web_search': True, 'documents': [Document(metadata={}, page_content='축구에서 파울은 심판에 의해 판정되며, 여러 종류의 반칙이 존재합니다. 아래는 주요 축구 파울의 기준입니다. 1. 킥킹(Kicking): 상대 선수를 차는 행위. 2. 트립핑(Tripping): 상대 선수를 걸려 넘어뜨리는 행위. 3. 점핑(Jumping): 상대를 향해 점프하는 행위. 4.\n축구에서 단순 파울이 발생되면 파울의 종류, 파울 위치에 따라 직접 프리킥 또는 간접 프리킥 선언이 내려지게 된다. ... 레드카드 발급 기준은 옐로카드 발급 규정과 동일하다. 이 둘의 차이는 위반의 수위와 위반 상황의 중대성 및 영향성에 의해 구분된다.\n사실 축구에서 가장 말이 많은 부분 중의 하나로, 파울 선언에 있어서 주심의 재량권이 어떤 스포츠보다도 강력한 점이 있다. ... 심판들이 부는 파울의 기준도 상대적으로 덜 엄격한 편이다. 또한 이는 타리그에서 이적해오는 선수들이 pl 적응에 애를 먹는\n축구는 전 세계에서 가장 인기 있는 스포츠 중 하나로, 그만큼 규칙과 판정에 대한 논란도 많습니다.특히 파울은 경기의 흐름을 바꿀 수 있는 중요한 요소입니다.이번 포스팅에서는 축구 파울의 역사와 적용 기준, 그리고 좋은 사례와 나쁜 사례를 살펴보겠습니다. 축구에서 파울이란 선수의 행동이\n오늘은 축구에서 파울의 개념에 대해 선수의 관점에서 살펴보고, 그것의 의미, 그리고 이를 피하기 위한 전략에 대해 알아보도록 하겠습니다. 파울에 대해 더 깊이 이해함으로써, 선수들은 경기력을 향상시키고 공정하고 즐거운 경기를 진행할 수 있습니다.')]}4개의 문서가 모두 question과 relevant하지 않다고 나왔으며 websearch를 수행하게 된다. 그리고 웹검색을 통해 질문에 대한 답변을 찾아서 generate 노드에서 응답결과가 출력이 된다.
langgraph는 아래와 같이 실행이 된다.