ChatGPT and LangChain: The Complete Developer's Masterclass 강좌의 일부를 요약한 내용이다.
Pipfile 정의
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
langchain = "==0.1.16"
openai = "==1.21.2"
langchain-openai = "==0.1.3"
python-dotenv = "==1.0.0"
chromadb = "*"
langchain-community = "==0.0.33"
[dev-packages]
[requires]
python_version = "3.12"pipenv install로 패키지 설치
- 경제상식.txt 로딩
- 글자를 짜른다
- 임베딩하여 ChromaDB에 넣는다.
- 문서 내용 검색
문서 생성
우선 아래 사이트의 경제 상식 내용을 가져다가 경제상식.txt로 만들자.
https://steemit.com/economic/@badajin79/71rcdv
[경제상식.txt]
1.대체재와 보완재 : 대체재는 서로 다른 재화인데 동일한 효과를 내는것으로 꿩대신 닭과 같은 관계를 말하고 보완재는 2가지 이상의 재화를 같이 사용해서 하나의 효용을 얻을 수 있을때 사용하는 단어로 "바늘과 실" 같은 관계를 말합니다.
2.블랙 컨슈머(black consumer) : 자신이 구매한 상품의 교환이나 보상금을 목적으로, 의도적으로 기업에 악성 민원을 제기하는 소비자를 말함
3.프로슈머(prosumer) : 상뭄 제조과정에 소비자가 깊숙이 관여해서 자신이 원하는 대로 제품을 생산해내는 '생산적 소비자'를 말함
4.크리슈머(cresumner) : '창조적 소비자'라는 개념으로 기존의 상품을 변형(리폼)해 자신만의 상품으로 만들거나 두 가지 이상의 상품으로 결합하거나 구매한 컨텐츠를 편집하거나 재설정하여 새로운 컨텐츠로 재제작 해내는 총체적인 소비자를 일컷는 말
5.베블런 효과(Veblen effect) : 일반적으로 가격이 오르면 수요가 줄어들어야 하는데 가격이 올라도 수요에 변화가 없는 현상을 베블런 효과라고 합니다. 상층계급의 사회적 지위를 과시하기 위한 목적으로 소비하는 형태로 명품은 비쌀수록 잘 팔리는 현상등이 베블른 효과의 예시라고 하겠음문서 로딩 & 짜르기
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1,
chunk_overlap=0
)
loader = TextLoader("경제상식.txt")
docs = loader.load_and_split(
text_splitter=text_splitter
)문서를 로딩하는 데 TextLoader를 사용한다.
TextLoader를 load하고 split할 때 CharacterTextSplitter를 사용한다.
CharacterTextSplitter에 사용된 파라미터는 3가지가 있다.
- separator : 분할된 각 청크를 구분할 때 기준이 되는 문자열이다.
- 여기서는
\n이므로 캐리지 리턴값을 기준으로 분할한다. - 만일 글자를 기준으로 분할하려면 빈 문자열(
'')을 사용하면 된다.
- 여기서는
- chunk_size: 각 청크의 최대 길이이다.
- 여기서는
1으로 설정되어 있으므로, 라인 당 하나의 청크가 생성된다. - 만일
500이면 최대 500자까지의 텍스트가 하나의 청크에 포함된다.
- 여기서는
- chunk_overlap: 인접한 청크 사이에 중복으로 포함될 문자의 수이다.
- 여기서는
0이므로 중복되지 않는다. - 만일
100으로 설정되어 있으면, 각 청크들은 연결 부분에서 100자가 중복된다.
- 여기서는
Embedding
embedding은 OpenAIEmbeddings를 사용할 것이다.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
emb = embeddings.embed_query("hi there")이렇게 실행하면 아래와 가이 출력이 된다.
[-0.04966343248080002, -0.0019060871770466114, -0.027579110414716022, -0.0429066796781429, -0.020506870223842972, 0.02421388056299324,
...
]OpenAIEmbeddings는 1536 차원이다. 이렇게 embedding을 한 결과를 Vector Store에 저장을 한다.
Vector DB
Vector Store는 데이터베이스이며 embedding을 하는 용도로 사용된다. 사용자가 질문을 하면 질문을 embedding을 하고 Vector Store에서 가장 유사한 정보를 찾는다. 여기서는 VectorDB로 Chroma를 사용한다.
ChromaDB는 내부적으로 SQLite를 사용하며 embedding을 저장을 한다.
우선 chromeDB를 설치하자.
pipenv install chromaDB그리고 소스에 chromaDB를 사용하는 로직을 추가하고 문서 내용을 짜른 내용을 ChromaDB에 저장을 하자.
from langchain.vectorstores.chroma import Chroma
...
db = Chroma.from_documents(
docs,
embedding=embeddings,
persist_directory="emb"
)from_documents는 문서의 내용을 embedding하라고 지시하는 것이다. from_documents를 호출하는 순간 OpenAI에 접속하여 embedding을 할 것이다. OpenAIEmbedding을 사용하면 비용이 약간 든다. 비용은 $0.00002 / 1K tokens 이다.
persist_directory는 SQLite가 생성되는 이름이다.
검색
다음으로 검색을 해볼 것이다.
검색을 할 때는 similarity_search_with_score를 사용하면 된다.
results = db.similarity_search_with_score("한 나라의 경제 동향의 현상 분석 및 물가 실업률 고용율을 연구하는 것을 뭐라고 하나?")
for result in results:
print("\n")
print(result[1])
print(result[0].page_content)실행하면 아래와 같이 검색이 된다.
0.30486595379597875
19.미시경제학(micro-economics), 거시경제학(macro-economics) : 미시경제학은 숲속의 나무를 보는 것으로 경제활동 주체를 개인, 기업 등 구분해서 분석하고 가격을 비롯해 매출, 가계소득 등의 수치에 의미를 둡니다. 반면에 거시경제학은 숲을 보는 것으로 한 나라의 전체의 경제동향과 현상을 분석하고 국내총생산, 물가, 실업률, 고용율, 경제성장, 국제수지, 환율 등을 연구하는 학문
0.36587780576022694
5.베블런 효과(Veblen effect) : 일반적으로 가격이 오르면 수요가 줄어들어야 하는데 가격이 올라도 수요에 변화가 없는 현상을 베블런 효과라고 합니다. 상층계급의 사회적 지위를 과시하기 위한 목적으로 소비하는 형태로 명품은 비쌀수록 잘 팔리는 현상등이 베블른 효과의 예시라고 하겠음
0.37741441207315024
6.레드오션(red ocean) : 붉은 바다라는 뜻으로 산업이 이미 자리 잡은 상태에서 경쟁자가 많아 경쟁이 과열되거나 치열해 지는 상태를 말함
0.37985695761932586
8.퍼플오션(purple ocean) : 레드와 블루를 썩으면 나오는 보라빛 바다라는 뜻으로 레드오션과 블루오션의 장점을 모아 놓은 곳으로 이미 포화상태에 진입해 경쟁이 치열한 기존 시장에서 새로운 기술이나 아이디어를 활용해 독창적인 시장을 개척하는 것을 말함30486595379597875는 질문과의 유사성을 나타내고 Vector DB에 따라 다른 값을 나타낼 것이다. 4개의 검색결과가 나온다. 만일 1개만 출력되길 원한다면 아래와 같이 k값을 추가하면 된다.
results = db.similarity_search_with_score(
"한 나라의 경제 동향의 현상 분석 및 물가 실업률 고용율을 연구하는 것을 뭐라고 하나?",
k=1
)여기서 위 코드를 여러번 실행하다 보면 출력 결과에 첫 번째, 두 번째 결과의 내용이 중복되는 것을 확인할 수 있다.
왜 이런 일이 일어나는 것일까? 그 이유는 실행할 때마다 ChromaDB에 새로 embedding을 하고 추가하기 때문이다. 몇 번 더 실행하면 모든 결과가 같은 내용이 출력될 것이다.
중복 제거
위에서 나타난 중복을 제거해보자. 우선 emb 디렉토리를 삭제하고 main.py를 한번만 실행을 한다. 그리고 prompt.py라는 파일을 생성한다.
prompt.py에서는 문서의 내용을 ChromaDB에 추가하지 않는다. main.py에서 이미 추가했다.
처리 방식은 아래와 같다.
우선 사용자 질문을 Vector Store에서 가장 유사한 질문을 찾아낸다. 그런 다음 ChatPromptTemplate으로 넣는다. System Message에 Vector Store에서 찾은 내용을 fact에 넣는다. 또한 사용자 메시지에 question에 질문 내용을 넣는다. 그런 다음 LLMChain으로 넣는다.
SystemMessagePromptTemplate의 Use the following ...와 HumanMessagePromptTemplate의 Here is the User... 는 LangChain에서 자동으로 넣어주는 프롬프트이다.
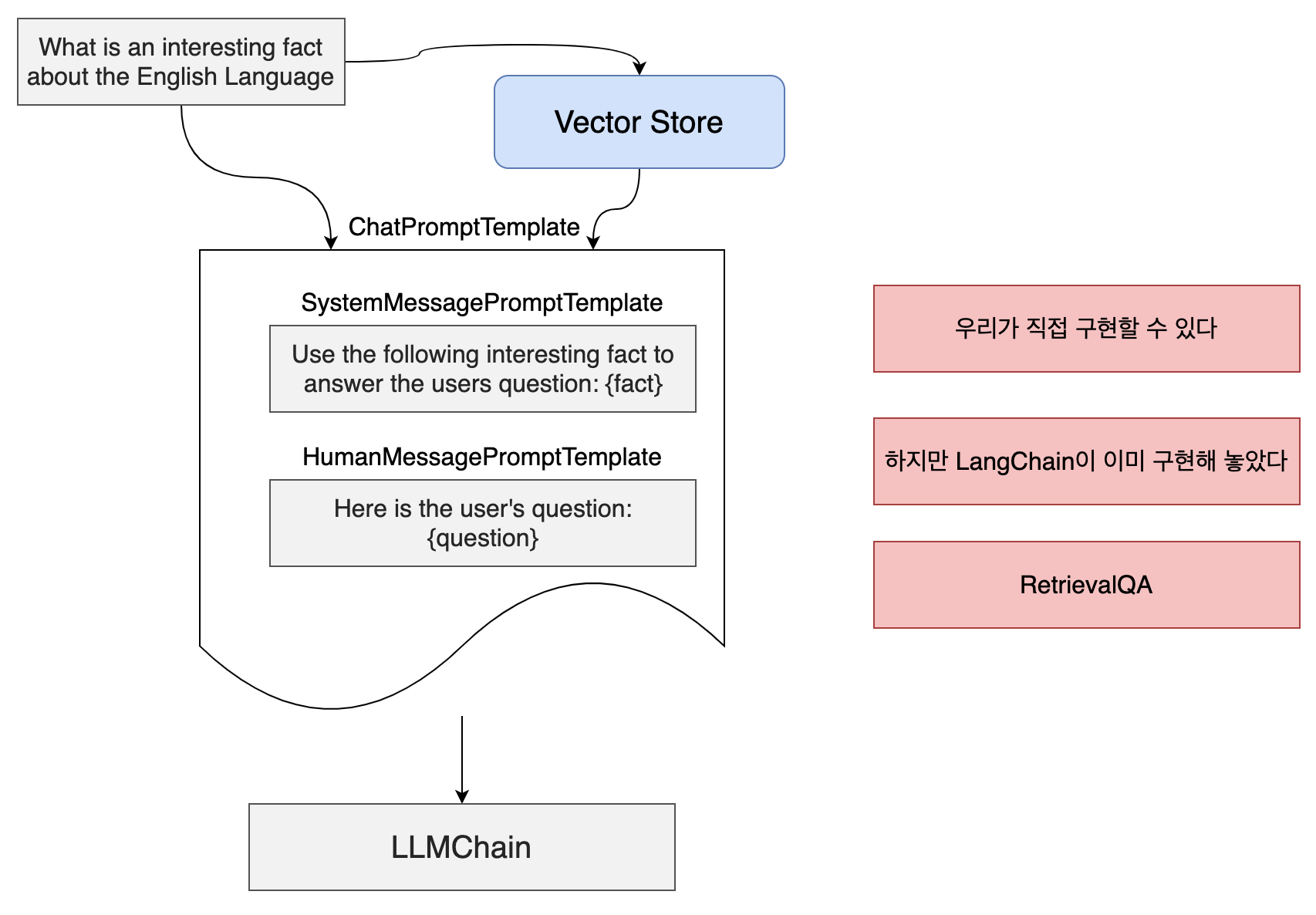
이런 방식으로 직접 구현을 해도 되지만 LangChain이 이미 만들어 놓았다. LangChain이 builtin class이며 처리방식은 위의 그림과 같다.
- Vector Store에 접속
- 사용자 질문을 embedding 한다
- 유사한 문서를 검색하고
- 검색 결과를 SystemMessagePromptTemplate에 넣는다.
- 사용자 질문을 UserMessagePromptTemplate에 넣는다.
- 전체를 LLMChain에 넣는다.
위의 구성방식을 RetrievalQA Chain이라고 한다.
RetrievalQA를 사용하면 ChatPromptTemplate을 직접적으로 사용할 필요가 없다.
아래는 prompy.py 소스 내용이다.
from langchain.vectorstores.chroma import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenv
import langchain
langchain.debug = True
load_dotenv()
chat = ChatOpenAI()
embeddings = OpenAIEmbeddings()
db = Chroma(
persist_directory="emb",
embedding_function=embeddings
)
retriever = db.as_retriever()
chain = RetrievalQA.from_chain_type(
llm=chat,
retriever=retriever,
chain_type="stuff"
)
result = chain.run("한 나라의 경제 동향의 현상 분석 및 물가 실업률 고용율을 연구하는 것을 뭐라고 하나?")
print(result)prompt.py를 실행해보면 아래의 결과가 출력된다.
An interesting fact about the English language is that the word "dreamt" is the only English word that ends with the letters "mt."두번 실행해도 동일한 결과가 출력된다.
langchain.debug = True로 실행해보면, System, Human 메시지가 구성되는 것을 알 수 있다.
{
"prompts": [
"System: Use the following pieces of context to answer the user's question. \nIf you don't know the answer, just say that you don't know, don't try to make up an answer.\n----------------\n19.미시경제학(micro-economics), 거시경제학(macro-economics) : 미시경제학은 숲속의 나무를 보는 것으로 경제활동 주체를 개인, 기업 등 구분해서 분석하고 가격을 비롯해 매출, 가계소득 등의 수치에 의미를 둡니다. 반면에 거시경제학은 숲을 보는 것으로 한 나라의 전체의 경제동향과 현상을 분석하고 국내총생산, 물가, 실업률, 고용율, 경제성장, 국제수지, 환율 등을 연구하는 학문\n\n5.베블런 효과(Veblen effect) : 일반적으로 가격이 오르면 수요가 줄어들어야 하는데 가격이 올라도 수요에 변화가 없는 현상을 베블런 효과라고 합니다. 상층계급의 사회적 지위를 과시하기 위한 목적으로 소비하는 형태로 명품은 비쌀수록 잘 팔리는 현상등이 베블른 효과의 예시라고 하겠음\n\n6.레드오션(red ocean) : 붉은 바다라는 뜻으로 산업이 이미 자리 잡은 상태에서 경쟁자가 많아 경쟁이 과열되거나 치열해 지는 상태를 말함\n\n8.퍼플오션(purple ocean) : 레드와 블루를 썩으면 나오는 보라빛 바다라는 뜻으로 레드오션과 블루오션의 장점을 모아 놓은 곳으로 이미 포화상태에 진입해 경쟁이 치열한 기존 시장에서 새로운 기술이나 아이디어를 활용해 독창적인 시장을 개척하는 것을 말함\nHuman: 한 나라의 경제 동향의 현상 분석 및 물가 실업률 고용율을 연구하는 것을 뭐라고 하나?"
]
}Retriever 란?
Retriever는 String을 인수로 받아서 연관성 있는 문서를 찾아주는 객체이다.
Vector DB의 종류는 수없이 많다. retriever는 다양한 Vector DB에서 검색을 할 수 있게 해주는 객체이다. 사용하는 Vector DB가 바뀌더라도 retriever를 통해 동일하게 검색을 할 수 있다.
retriever가 되기 위해서는 get_relevant_document 함수가 있어야 한다. 즉, 인터페이스 같은 걸 구현해야 한다는 것이다.
ChromaDB에서 유사도 검색 시 db.similarity_search()를 사용했었다. 하지만 다른 Vector DB는 다른 함수를 사용한다. 그래서 모든 Vector DB에서 동일한 인터페이스를 통해 검색을 하기 위해 get_relevant_document를 통해 검색을 하는 것이다.
RedundantFilterRetriever로 중복 제거
Vector DB 검색 시 유사한 문서는 제거할 수 있는 filter를 만들어보자. 아래와 같이 redundant_filter_retriever.py 파일을 만든다.
# redundant_filter_retriever.py
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.chroma import Chroma
from langchain.schema import BaseRetriever
class RedundantFilterRetriever(BaseRetriever):
embeddings: Embeddings
chroma: Chroma
def get_relevant_documents(self, query):
# 'query'에 대해 embeddings 계산
emb = self.embeddings.embed_query(query)
# embedding을 가지고 max_marginal_relevance_search_by_vector에 주입
return self.chroma.max_marginal_relevance_search_by_vector(
embedding=emb, lambda_mult=0.8
)
async def aget_relevant_documents(self):
return []그리고 위에서 db.as_retriever() 부분을 filter로 변경하자.
from redundant_filter_retriever import RedundantFilterRetriever
...
# retriever = db.as_retriever()
retriever = RedundantFilterRetriever(
embeddings=embeddings,
chroma=db
)그리고 실행을 해보면 잘 실행되는데, langchain.debug = True를 하고 System 메시지를 보면 중복 데이터가 없어진 것을 확인할 수 있다.


