LangChain에서 자주 사용되는 네 가지 메서드인 invoke, ainvoke, stream, astream를 실행할 때의 실제 llm을 호출하지 않고 fake llm을 통해 실행시간 테스트를 해보자.
fake llm은 실제 llm을 호출하는 방식이 아닌 사전에 응답을 정의하고 해당 응답을 리턴하는 방식이다. 실제 llm은 호출하지 않는다.
기본 코드
실행시간을 측정하기 위한 데코레이터 함수를 두 개 만들었다.
import time
from functools import wraps
def elapsed_time(func):
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.perf_counter()
result = func(*args, **kwargs)
end_time = time.perf_counter()
print("Sync execution time:", (end_time - start_time))
return result
return wrapper
def elapsed_time_async(func):
@wraps(func)
async def wrapper(*args, **kwargs):
start_time = time.perf_counter()
result = await func(*args, **kwargs)
end_time = time.perf_counter()
print("Async execution time:", (end_time - start_time))
return result
return wrapperelapsed_time는 동기 함수 실행 시 실행시간을 측정하기 위한 것이고, elapsed_time_async는 비동기 함수 실행 시 실행시간을 측정하기 위한 것이다.
그리고 아래 코드는 4가지 유형에 대한 테스트를 위한 기본코드이다.
# 가짜 응답 리스트 정의
fake_responses = [
"서울은 대한민국의 수도입니다. 대한민국의 정치, 경제, 문화의 중심지로서 중요한 역할을 하고 있습니다. 추가로 궁금한 사항이 있으시면 말씀해 주세요!"
]
# LLM 호출용 FakeListLLM
llm = FakeListLLM(
responses=fake_responses,
)
# streaming 용 FakeStreamingListLLM
llm_streaming = FakeStreamingListLLM(responses=fake_responses)
template = "한국의 수도는?"
request_count = 10
sleep_time = 0.5- 모든 요청은
10번실행한다. (request_count = 10) - 실행시간을 실제 실행시간과 유사하게 sleep을 둔다. (0.5초, sleep_time = 0.5)
1. invoke: 동기적 요청 처리
invoke는 LangChain에서 가장 기본적인 메서드로, 동기적으로 언어 모델에 요청을 보내고 결과를 반환한다.
사용 예시
@elapsed_time
def invoke_sync():
for i in range(request_count):
result = llm.invoke(template)
sleep(sleep_time)
print(result)
invoke_sync()응답결과
한국의 수도는 서울입니다. 서울은 대한민국의 정치, 경제, 문화의 중심지로서 중요한 역할을 하고 있습니다.
한국의 수도는 서울입니다. 서울은 대한민국의 정치, 경제, 문화의 중심지로서 중요한 역할을 하고 있습니다.
<계속>
Sync execution time: 5.04580648790579310번 실행한 시간이 5초 정도 걸린 것을 확인할 수 있다.
2. ainvoke: 비동기적 요청 처리
ainvoke는 비동기 방식으로 언어 모델에 요청을 보내고 결과를 반환한다. 아래 코드 중 asyncio.gather는 비동기 작업을 한번에 실행하고자 할 때 사용할 수 있다.
사용 예시
async def ainvoke():
result = await llm.ainvoke(template)
print(result)
@elapsed_time_async
async def invoke_async():
tasks = [ainvoke() for _ in range(request_count)]
await asyncio.gather(*tasks)
asyncio.run(invoke_async())응답결과
한국의 수도는 서울입니다. 서울은 대한민국의 정치, 경제, 문화의 중심지로서 중요한 역할을 하고 있습니다.
한국의 수도는 서울입니다. 서울은 대한민국의 정치, 경제, 문화의 중심지로서 중요한 역할을 하고 있습니다.
<계속>
Async execution time: 0.509881180012598610번 실행한 시간이 0.5초 정도 걸린 것을 확인할 수 있다.
3. stream: 동기적 스트리밍
stream은 동기적으로 언어 모델의 응답을 스트리밍 방식으로 처리할 수 있게 된다.
사용 예시
@elapsed_time
def stream_sync():
for i in range(request_count):
for chunk in llm_streaming.stream(template):
print(chunk, end="", flush=True)
print("\n", end="", flush=True)
sleep(sleep_time)응답결과
서울은 대한민국의 수도입니다. 대한민국의 정치, 경제, 문화의 중심지로서 중요한 역할을 하고 있습니다. 추가로 궁금한 사항이 있으시면 말씀해 주세요!
서울은 대한민국의 수도입니다. 대한민국의 정치, 경제, 문화의 중심지로서 중요한 역할을 하고 있습니다. 추가로 궁금한 사항이 있으시면 말씀해 주세요!
<계속>
Sync execution time: 5.05140893498901310번 실행한 시간이 5초 정도 걸린 것을 확인할 수 있다.
4. astream: 비동기적 스트리밍
astream은 비동기 방식으로 스트리밍 데이터를 처리할 수 있게 한다. 아래 코드 중 asyncio.gather는 비동기 작업을 한번에 실행하고자 할 때 사용할 수 있다.
사용 예시
async def astream():
async for chunk in llm_streaming.astream(template):
print(chunk, end="", flush=True)
print("\n", end="", flush=True)
await asyncio.sleep(sleep_time)
@elapsed_time_async
async def stream_async():
tasks = [astream() for _ in range(request_count)]
await asyncio.gather(*tasks)응답결과
서울은 대한민국의 수도입니다. 대한민국의 정치, 경제, 문화의 중심지로서 중요한 역할을 하고 있습니다. 추가로 궁금한 사항이 있으시면 말씀해 주세요!
서울은 대한민국의 수도입니다. 대한민국의 정치, 경제, 문화의 중심지로서 중요한 역할을 하고 있습니다. 추가로 궁금한 사항이 있으시면 말씀해 주세요!
<계속>
.
Async execution time: 0.512239537085406510번 실행한 시간이 0.5초 정도 걸린 것을 확인할 수 있다.
요약
| 함수명 | 동기/비동기 | 실행시간 (초) |
|---|---|---|
invoke |
동기 | 5.045806487905793 |
ainvoke |
비동기 | 0.5098811800125986 |
stream |
동기 | 5.051408934989013 |
astream |
비동기 | 0.5122395370854065 |
위 결과는 실행환경에 따라 시간이 달라질 수 있다.
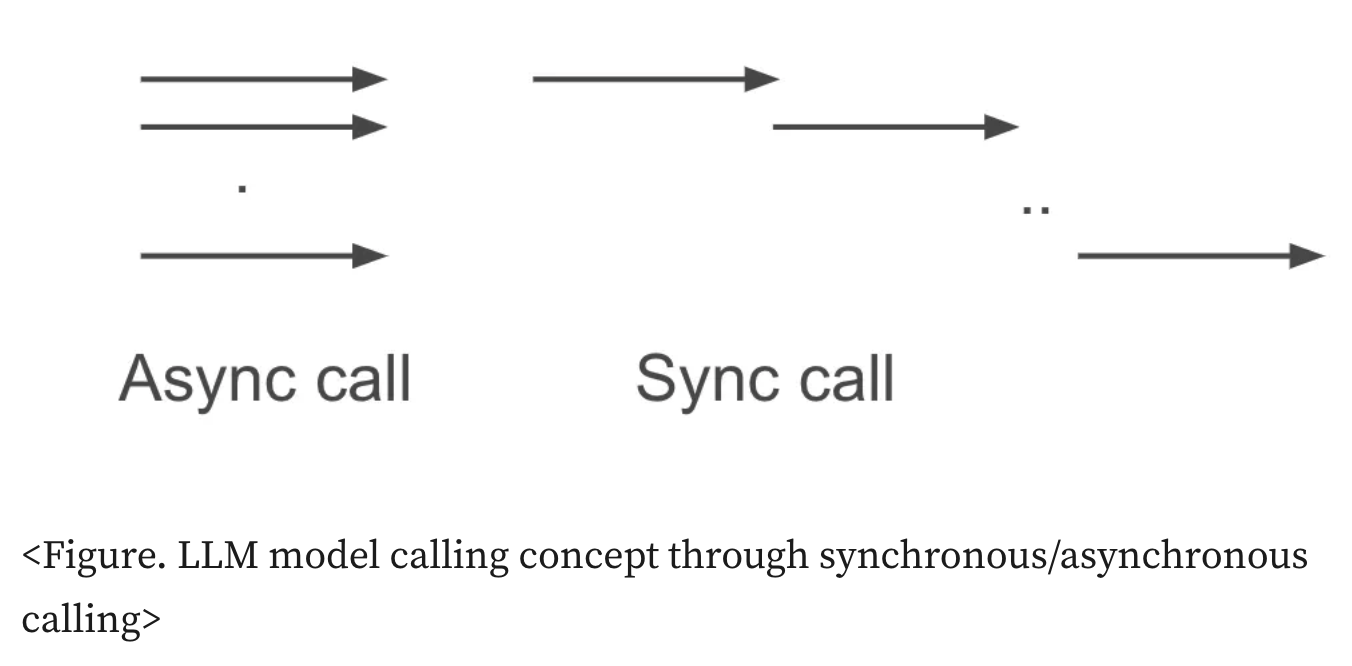
동기 호출은 응답을 받고 나서 다음 코드를 실행할 수 있지만 비동기의 경우 동시에 실행할 수 있으므로 빠르게 실행할 수 있다. 즉, 10개의 호출을 비동기는 동시에 실행할 수 있지만, 동기의 경우 1개의 호출이 끝나면 다음 로직을 호출하는 방식이다.

