langgraph의 공식문서를 번역해 놓은 자료입니다. 예제 일부는 변경하였고, 필요한 경우 부연 설명을 추가하였습니다. 문제가 되면 삭제하겠습니다.
https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_agentic_rag/
Retrieval Agent는 인덱스에서 검색할지 여부에 대한 결정을 내리고 싶을 때 유용하다.
Retrieval Agent를 구현하려면 LLM에 검색 도구에 대한 접근 권한을 부여하면 된다.
이를 LangGraph에 통합할 수 있다.
Retriever
우선 블로그 포스트를 인덱싱한다.
from dotenv import load_dotenv
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
load_dotenv()
urls = [
"https://namu.wiki/w/%EC%95%BC%EA%B5%AC/%EA%B2%BD%EA%B8%B0%20%EB%B0%A9%EC%8B%9D" # 야구/경기 방식
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500, chunk_overlap=100
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()그리고 나서 retrieval 도구를 생성한다.
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"retrieve_baseball",
"Search and return information about game, rules on baseball.",
)
tools = [retriever_tool]
create_retriever_tool는 뭘까?
소스코드의 docstring을 보면 아래와 같이 되어 있다.
"""Create a tool to do retrieval of documents. Args: retriever: The retriever to use for the retrieval name: The name for the tool. This will be passed to the language model, so should be unique and somewhat descriptive. description: The description for the tool. This will be passed to the language model, so should be descriptive. document_prompt: The prompt to use for the document. Defaults to None. document_separator: The separator to use between documents. Defaults to "\n\n". Returns: Tool class to pass to an agent. """문서 검색을 하는 도구를 생성할 때 사용한다. description에 이 문서에 대한 설명을 잘 적으면 질문의 내용에서 문서를 검색할 필요가 있을 때 이 툴을 사용하게 된다.
그리고 리턴값으로 agent에 전달할 Tool 클래스를 리턴한다.
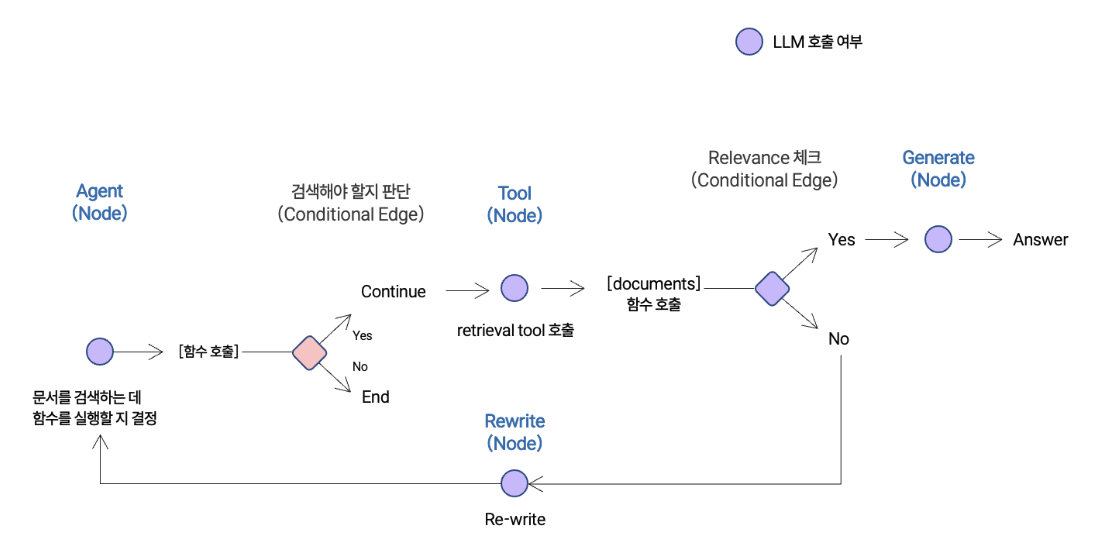
Agent State
그래프를 정의한다. 각 노드에 전달되는 상태(State) 객체이다. 상태는 메시지(messages) 목록이 될 것이다. 그래프의 각 노드는 여기에 추가할 것이다.
from typing import Annotated, Sequence
from typing_extensions import TypedDict
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]노드(Node)와 엣지(Edge)
Agentic RAG 그래프를 다음과 같이 나타낼 수 있다.
- 상태(state)는 일련의 메시지(messages) 모음이다.
- 각 노드는 상태를 업데이트(추가)한다.
- 조건부 엣지(conditional edges)는 다음에 접근할 노드를 결정한다.
Langchain에서 Pydantic 사용
이 노트북은 Pydantic v2의
BaseModel을 사용하며, 이는langchain-core >= 0.3이 필요하다.langchain-core < 0.3을 사용하면 Pydantic v1과 v2의BaseModel혼합으로 인해 오류가 발생한다.
from typing import Annotated, Literal, Sequence
from typing_extensions import TypedDict
from langchain import hub
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langgraph.prebuilt import tools_condition
### Edges
def grade_documents(state) -> Literal["generate", "rewrite"]:
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (messages): The current state
Returns:
str: A decision for whether the documents are relevant or not
"""
print("---CHECK RELEVANCE---")
# Data model
class grade(BaseModel):
"""Binary score for relevance check."""
binary_score: str = Field(description="Relevance score 'yes' or 'no'")
# LLM
model = ChatOpenAI(temperature=0, model="gpt-4o-mini", streaming=True)
# LLM with tool and validation
llm_with_tool = model.with_structured_output(grade)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question. \n
Here is the retrieved document: \n\n {context} \n\n
Here is the user question: {question} \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""",
input_variables=["context", "question"],
)
# Chain
chain = prompt | llm_with_tool
messages = state["messages"]
last_message = messages[-1]
question = messages[0].content
docs = last_message.content
scored_result = chain.invoke({"question": question, "context": docs})
score = scored_result.binary_score
if score == "yes":
print("---DECISION: DOCS RELEVANT---")
return "generate"
else:
print("---DECISION: DOCS NOT RELEVANT---")
print(score)
return "rewrite"
### Nodes
def agent(state):
"""
Invokes the agent model to generate a response based on the current state. Given
the question, it will decide to retrieve using the retriever tool, or simply end.
Args:
state (messages): The current state
Returns:
dict: The updated state with the agent response appended to messages
"""
print("---CALL AGENT---")
messages = state["messages"]
model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4o-mini")
model = model.bind_tools(tools)
response = model.invoke(messages)
# list를 리턴하면 기존 messages list에 추가된다.
return {"messages": [response]}
def rewrite(state):
"""
Transform the query to produce a better question.
Args:
state (messages): The current state
Returns:
dict: The updated state with re-phrased question
"""
print("---TRANSFORM QUERY---")
messages = state["messages"]
question = messages[0].content
msg = [
HumanMessage(
content=f""" \n
Look at the input and try to reason about the underlying semantic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question: """,
)
]
# Grader
model = ChatOpenAI(temperature=0, model="gpt-4o-mini", streaming=True)
response = model.invoke(msg)
return {"messages": [response]}
def generate(state):
"""
Generate answer
Args:
state (messages): The current state
Returns:
dict: The updated state with re-phrased question
"""
print("---GENERATE---")
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0, streaming=True)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}
print("*" * 20 + "Prompt[rlm/rag-prompt]" + "*" * 20)
prompt = hub.pull("rlm/rag-prompt").pretty_print() # Show what the prompt looks like********************Prompt[rlm/rag-prompt]********************
================================ Human Message =================================
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:Graph
- 에이전트인
call_model로 시작한다. - 에이전트는 함수를 호출할지 결정한다.
- 만약 그렇다면, 도구(조회기)를 호출하는 동작(
action)을 수행한다. - 그런 다음 도구의 출력을 메시지(
state)에 추가하여 에이전트를 호출한다.
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import ToolNode
# 그래프 정의
workflow = StateGraph(AgentState)
# 노드 정의
workflow.add_node("agent", agent) # agent
retrieve = ToolNode([retriever_tool])
workflow.add_node("retrieve", retrieve) # retrieval
workflow.add_node("rewrite", rewrite) # Re-writing the question
workflow.add_node(
"generate", generate
) # 문서가 적절할지 판단후 답변 생성
# agent 노드 연결
workflow.add_edge(START, "agent")
# 검색할 지 판단
workflow.add_conditional_edges(
"agent",
# agent 판단 평가
tools_condition, # 마지막 메시지에 tool_calls가 있는지 체크한다.
{
"tools": "retrieve",
END: END,
},
)
# Edges taken after the `action` node is called.
workflow.add_conditional_edges(
"retrieve",
grade_documents, # grade_documents 평가에서 문서가 질문과 관련성이 있으면 "generate"로, 관련 없으면 "rewrite"로 간다.
)
workflow.add_edge("generate", END)
workflow.add_edge("rewrite", "agent")
# Compile
graph = workflow.compile()from IPython.display import Image, display
try:
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass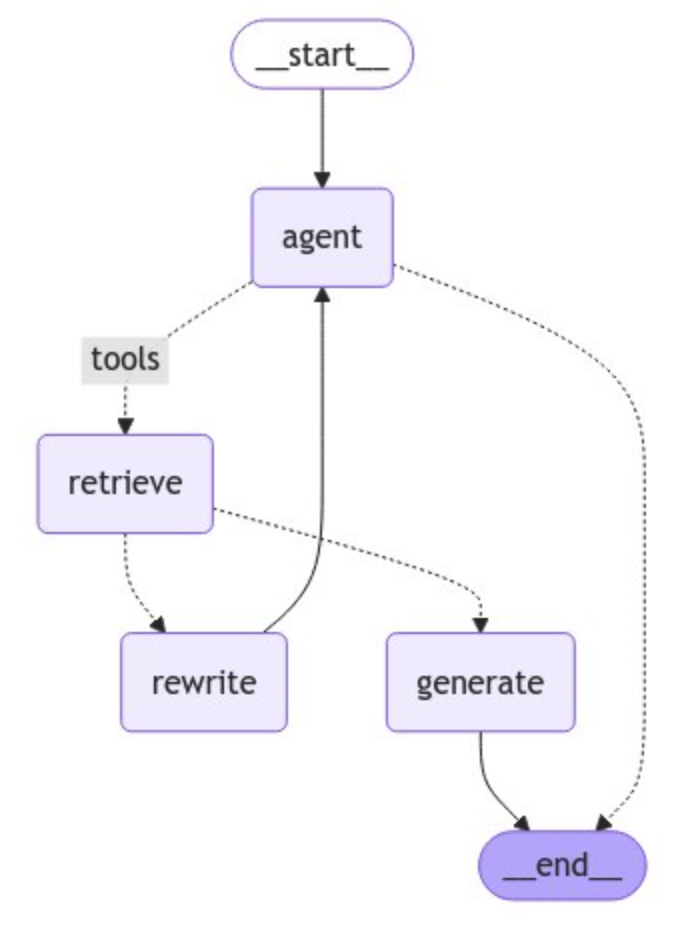
import pprint
inputs = {
"messages": [
("user", "야구에서 홈런은 뭐야?"),
]
}
for output in graph.stream(inputs):
for key, value in output.items():
pprint.pprint(f"Output from node '{key}':")
pprint.pprint("---")
pprint.pprint(value, indent=2, width=80, depth=None)
pprint.pprint("\n---\n")---CALL AGENT---
---- agent에서 받은 response ----
"Output from node 'agent':"
'---'
{ 'messages': [ AIMessage(content='', additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_vnTzC7H7nS6qdIRqDKeZGsgB', 'function': {'arguments': '{"query":"홈런"}', 'name': 'retrieve_baseball'}, 'type': 'function'}]}, response_metadata={'finish_reason': 'tool_calls', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_9b78b61c52'}, id='run-a3146cd4-67a2-4a4b-9c26-493b6daa8b0b-0', tool_calls=[{'name': 'retrieve_baseball', 'args': {'query': '홈런'}, 'id': 'call_vnTzC7H7nS6qdIRqDKeZGsgB', 'type': 'tool_call'}])]}
'\n---\n'
---CHECK RELEVANCE---
grade_documents#scored_result: binary_score='yes'
grade_documents#score: yes
---DECISION: DOCS RELEVANT---
"Output from node 'retrieve':"
'---'
{ 'messages': [ ToolMessage(content='공이 그라운드로 들어가는 경우에도 홈런으로 인정된다. 이를 확인하기 위해서 보통 단층 펜스 상단에 노란 줄을 긋고 줄을 넘어가면 홈런으로 인정하는 룰을 많이 쓴다.[27] 이중으로 펜스가 쳐진 경우는 예외. 획일적 구조로 지어진 한국과는 달리 미국은 구장마다 펜스의 생김새와 규정이 각각 달라서 이로 인해 이득과 손해를 보는 타자가 제법 있다. 참고로 홈런도 안타의 일종이다.파울(Foul)타자가 친 공이 파울 라인\n\n담장 안에 공이 떨어질 경우엔 수비수가 그동안 공을 처리하지 못할 정도로 멀리 오랫동안 처리할 타구를 보내야 한다. 현대 야구에서는 전자의 경우를 홈런으로 기록하고, 후자의 경우는 인사이드 파크 홈런으로 기록한다. 루상에 주자가 있으면 순서대로 진루하여 홈 플레이트를 밟으면 득점한다. 그렇기 때문에 만루홈런을[26] 치면 최대 4점을 득점할 수 있다. 다만 공의 착지점을 확인하기 애매할 때가 많은 만큼 이를\n\n덩굴을 기르고 있는 등[12] 구장 내에 특별한 구조물이 있으면 홈 구단은 그에 맞는 로컬룰을 제정할 수 있으며 그 로컬룰은 홈팀 원정팀 똑같이 적용된다. 홈팀 감독은 심판진과 상대팀 감독에게 로컬 룰을 미리 알려줘야 한다.3. 심판[편집]심판진은 보통 4심제[13][14][15]로 운영된다. 주심과 3명의 루심[16][17]으로 구성되며 경기를 관리한다.[18] 주심은 스트라이크와 볼, 힛 바이 피치, 홈에서 주자의 세이프와 아웃 등을 판정한다. 각\n\n경우(예를 들어 1사 1루 상황에서 우전 안타 - 주자가 2루를 지나 3루까지 가려다가 3루에서 죽은 경우)에는 타자에게는 안타를 인정한다.홈런(Home Run)수비수의 실책 없이 타자가 홈 베이스를 밟을 수 있게 공을 치는 것. 타자가 홈 베이스를 밟을 시간만큼 공을 치려면 수비가 못 잡도록 바운드가 되기 전에 아예 담장 밖으로 날려버리거나[25], 담장 안에 공이 떨어질 경우엔 수비수가 그동안 공을 처리하지 못할 정도로 멀리', name='retrieve_baseball', id='04396b2e-95c4-4f7d-b0fe-3adecbcdcc99', tool_call_id='call_vnTzC7H7nS6qdIRqDKeZGsgB')]}
'\n---\n'
---GENERATE---
---- generate에서 받은 docs ----
공이 그라운드로 들어가는 경우에도 홈런으로 인정된다. 이를 확인하기 위해서 보통 단층 펜스 상단에 노란 줄을 긋고 줄을 넘어가면 홈런으로 인정하는 룰을 많이 쓴다.[27] 이중으로 펜스가 쳐진 경우는 예외. 획일적 구조로 지어진 한국과는 달리 미국은 구장마다 펜스의 생김새와 규정이 각각 달라서 이로 인해 이득과 손해를 보는 타자가 제법 있다. 참고로 홈런도 안타의 일종이다.파울(Foul)타자가 친 공이 파울 라인
담장 안에 공이 떨어질 경우엔 수비수가 그동안 공을 처리하지 못할 정도로 멀리 오랫동안 처리할 타구를 보내야 한다. 현대 야구에서는 전자의 경우를 홈런으로 기록하고, 후자의 경우는 인사이드 파크 홈런으로 기록한다. 루상에 주자가 있으면 순서대로 진루하여 홈 플레이트를 밟으면 득점한다. 그렇기 때문에 만루홈런을[26] 치면 최대 4점을 득점할 수 있다. 다만 공의 착지점을 확인하기 애매할 때가 많은 만큼 이를
덩굴을 기르고 있는 등[12] 구장 내에 특별한 구조물이 있으면 홈 구단은 그에 맞는 로컬룰을 제정할 수 있으며 그 로컬룰은 홈팀 원정팀 똑같이 적용된다. 홈팀 감독은 심판진과 상대팀 감독에게 로컬 룰을 미리 알려줘야 한다.3. 심판[편집]심판진은 보통 4심제[13][14][15]로 운영된다. 주심과 3명의 루심[16][17]으로 구성되며 경기를 관리한다.[18] 주심은 스트라이크와 볼, 힛 바이 피치, 홈에서 주자의 세이프와 아웃 등을 판정한다. 각
경우(예를 들어 1사 1루 상황에서 우전 안타 - 주자가 2루를 지나 3루까지 가려다가 3루에서 죽은 경우)에는 타자에게는 안타를 인정한다.홈런(Home Run)수비수의 실책 없이 타자가 홈 베이스를 밟을 수 있게 공을 치는 것. 타자가 홈 베이스를 밟을 시간만큼 공을 치려면 수비가 못 잡도록 바운드가 되기 전에 아예 담장 밖으로 날려버리거나[25], 담장 안에 공이 떨어질 경우엔 수비수가 그동안 공을 처리하지 못할 정도로 멀리
Sync execution time: 2.1106324589345604
"Output from node 'generate':"
'---'
{ 'messages': [ '홈런은 수비수의 실책 없이 타자가 홈 베이스를 밟을 수 있게 공을 치는 것이다. 타자가 홈 베이스를 밟을 '
'시간만큼 공을 침으로써 득점을 한다. 만루홈런을 쳐도 최대 4점을 득점할 수 있다.']}
'\n---\n'위의 실행로직을 다시 정리하면
아래와 같이 3가지 case로 실행이 될 수 있다.
Case 1: tool이 사용되는 경우 (relevance check=yes)
Case 2: tool이 사용되지만 relevance check가 no이여서 rewrite가 되는 경우
Case 3: tool이 사용되지 않는 경우
Case 1: tool이 사용되는 경우
agent --> relevance --> generate
Question: 야구에서 홈런은 뭐야?
1. 최초 실행 시 agent가 실행
def agent(state):
print("---CALL AGENT---")
messages = state["messages"]
model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4o-mini", verbose=True)
model = model.bind_tools(tools)
response = model.invoke(messages) #
return {"messages": [response]}위에서 response로 tool_calling응답이 내려온다.
content='' additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_4YpT5rXOaHBVGeZyqtv0AtbK', 'function': {'arguments': '{"query":"홈런"}', 'name': 'retrieve_baseball'}, 'type': 'function'}]} response_metadata={'finish_reason': 'tool_calls', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_9b78b61c52'} id='run-4205e712-e12c-4a4f-ac84-1ba5ea769272-0' tool_calls=[{'name': 'retrieve_baseball', 'args': {'query': '홈런'}, 'id': 'call_4YpT5rXOaHBVGeZyqtv0AtbK', 'type': 'tool_call'}]content 대신 tool_calls로 응답이 오면 해당 name(retrieve_blog_posts)의 tool이 실행이 된다.
messages에 tool_calls의 message가 추가된다.
2. 문서가 적절한 지 (Relevance를 체크)
retrieve한 문서가 사용자 질문과 관련있는지를 체크하여 yes or no로 응답을 받는다.
def grade_documents(state) -> Literal["generate", "rewrite"]:
# 검색한 문서가 질문과 관련성이 있는지 체크하는 Prompt
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question. \n
Here is the retrieved document: \n\n {context} \n\n
Here is the user question: {question} \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""",
input_variables=["context", "question"],
)
# Chain
chain = prompt | llm_with_tool
messages = state["messages"]
# message에는 3개의 message가 추가된다.
# 0: HumanMessage - 사용자 질문
# 1: AIMessage - tool_calls
# 2: ToolMessage - retrieve로 검색한 내용
last_message = messages[-1] # ToolMessage(content=retrieve로 검색한 내용)
# last_message에는 retrieve로 검색한 내용이 들어간다.
question = messages[0].content
docs = last_message.content
scored_result = chain.invoke({"question": question, "context": docs})
# retrieve로 검색한 내용이 사용자 질문과 관련성이 있는지 LLM을 통해 평가한다.
score = scored_result.binary_score
if score == "yes": # 관련성이 있으면 답변생성을 위해 generate 단계로 넘어간다.
print("---DECISION: DOCS RELEVANT---")
return "generate"
else: # 관련성이 없으면 질문 재작성을 위해 rewrite로 넘어간다.
print("---DECISION: DOCS NOT RELEVANT---")
print(score)
return "rewrite"---CHECK RELEVANCE---
grade_documents#scored_result: binary_score='yes'
grade_documents#score: yes
---DECISION: DOCS RELEVANT---3. 답변생성 generate
def generate(state):
messages = state["messages"] # 3개의 메시지. 질문, tool_calls, retrieve
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
prompt = hub.pull("rlm/rag-prompt") # rag를 위한 프롬프트
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, streaming=True)
rag_chain = prompt | llm | StrOutputParser()
# Run
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}---GENERATE---
---- generate에서 받은 docs ----
공이 그라운드로 들어가는 경우에도 홈런으로 인정된다. 이를 확인하기 위해서 보통 단층 펜스 상단에 노란 줄을 긋고 줄을 넘어가면 홈런으로 인정하는 룰을 많이 쓴다.[27] 이중으로 펜스가 쳐진 경우는 예외. 획일적 구조로 지어진 한국과는 달리 미국은 구장마다 펜스의 생김새와 규정이 각각 ....
"Output from node 'generate':"
'---'
{ 'messages': [ '홈런은 수비수의 실책 없이 타자가 홈 베이스를 밟을 수 있게 공을 치는 것이다. 타자가 홈 베이스를 밟을 '
'시간만큼 공을 침으로써 홈런을 기록할 수 있다. 만루홈런을 쳐도 최대 4점을 득점할 수 있다.']}
'\n---\n'Case 2: tool이 사용되지만 rewrite가 되는 경우
agent --> relevance --> rewrite --> generate
question: 야구 축구
1. 최초 실행 시 agent가 실행
def agent(state):
print("---CALL AGENT---")
messages = state["messages"]
model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4o-mini", verbose=True)
model = model.bind_tools(tools)
response = model.invoke(messages) #
return {"messages": [response]}위에서 response로 tool_calling응답이 내려온다.
content='' additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_mrTgBS1tTJBZwebRkqUbvdvA', 'function': {'arguments': '{"query": "야구"}', 'name': 'retrieve_baseball'}, 'type': 'function'}, {'index': 1, 'id': 'call_T22l9kqZOAir9HFu1UXrDams', 'function': {'arguments': '{"query": "축구"}', 'name': 'retrieve_baseball'}, 'type': 'function'}]} response_metadata={'finish_reason': 'tool_calls', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_9b78b61c52'} id='run-b6823a7e-0892-4eb1-8977-a270770eabce-0' tool_calls=[{'name': 'retrieve_baseball', 'args': {'query': '야구'}, 'id': 'call_mrTgBS1tTJBZwebRkqUbvdvA', 'type': 'tool_call'}, {'name': 'retrieve_baseball', 'args': {'query': '축구'}, 'id': 'call_T22l9kqZOAir9HFu1UXrDams', 'type': 'tool_call'}]2. 문서가 적절한 지 (Relevance를 체크)
retrieve한 문서가 사용자 질문과 관련있는지를 체크하여 yes or no로 응답을 받는다.
def grade_documents(state) -> Literal["generate", "rewrite"]:
...
scored_result = chain.invoke({"question": question, "context": docs})
score = scored_result.binary_score # no
if score == "yes": # 관련성이 있으면 답변생성을 위해 generate 단계로 넘어간다.
print("---DECISION: DOCS RELEVANT---")
return "generate"
else: # 관련성이 없으면 질문 재작성을 위해 rewrite로 넘어간다.
print("---DECISION: DOCS NOT RELEVANT---")
print(score)
return "rewrite"---CHECK RELEVANCE---
grade_documents#scored_result: binary_score='no'
grade_documents#score: no
---DECISION: DOCS NOT RELEVANT---
no3. rewrite
def rewrite(state):
messages = state["messages"] # 3개의 message
question = messages[0].content
msg = [
HumanMessage(
content=f""" \n
Look at the input and try to reason about the underlying semantic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question: """,
)
]
# Grader
model = ChatOpenAI(temperature=0, model="gpt-4o-mini", streaming=True)
response = model.invoke(msg)
print("---- rewrite response ----")
print(response)
return {"messages": [response]}---TRANSFORM QUERY---
---- rewrite response ----
content='어떤 스포츠가 더 재미있다고 생각하시나요, 야구와 축구 중에서?' additional_kwargs={} response_metadata={'finish_reason': 'stop', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_9b78b61c52'} id='run-62f54a55-6043-42e1-8117-74c5646e1d21-0'question은 "야구 축구"이고 rewrite한 question은 "어떤 스포츠가 더 재미있다고 생각하시나요, 야구와 축구 중에서?"라고 생성이 되었다.
4. 답변생성 generate
def generate(state):
messages = state["messages"] # 4개의 메시지.
# question, tool_calls, retrieve, rewrite된 question
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
prompt = hub.pull("rlm/rag-prompt") # rag를 위한 프롬프트
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, streaming=True)
rag_chain = prompt | llm | StrOutputParser()
# Run
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}---- agent에서 받은 response ----
content='야구와 축구는 각각의 매력이 있는 스포츠입니다. \n\n### 야구\n- **게임의 구조**: 야구는 두 팀이 번갈아 가며 공격과 수비를 하며, 주로 9이닝으로 구성됩니다. 각 팀은 3아웃이 될 때까지 공격을 계속합니다.\n- **전략**: 투수와 타자 간의 심리전이 중요한 요소이며, 각 팀의 전략에 따라 다양한 플레이가 이루어집니다.\n- **경기 시간**: 경기 시간은 정해져 있지 않지만, 평균적으로 3시간 정도 소요됩니다.\n\n### 축구\n- **게임의 구조**: 축구는 두 팀이 90분 동안 경기를 하며, 45분씩 두 개의 하프타임으로 나뉩니다. 득점이 더 많은 팀이 승리합니다.\n- **전략**: 팀워크와 빠른 패스, 드리블이 중요하며, 공격과 수비의 전환이 빠르게 이루어집니다.\n- **경기 시간**: 정해진 시간 내에 경기가 진행되며, 추가 시간이나 연장전이 있을 수 있습니다.\n\n각 스포츠는 팬들에게 다른 경험을 제공합니다. 야구는 느긋한 분위기에서 전략을 즐길 수 있고, 축구는 빠른 템포와 팀워크를 강조합니다. 어떤 스포츠가 더 재미있다고 느끼는지는 개인의 취향에 따라 다를 수 있습니다.' additional_kwargs={} response_metadata={'finish_reason': 'stop', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_9b78b61c52'} id='run-a74ce4e0-f5aa-40d2-bfdf-ea7414f1bd19-0'Case 3: tool이 사용되지 않는 경우
agent
question: 한국의 수도는?
이 질문은 retrieve를 하지 않고도 답변을 할 수 있다. 그래서 agent는 tool을 실행하지 않고 바로 답변을 한다.
1. 최초 실행 시 agent가 실행
def agent(state):
print("---CALL AGENT---")
messages = state["messages"]
model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4o-mini", verbose=True)
model = model.bind_tools(tools)
response = model.invoke(messages) #
return {"messages": [response]}여기서 tool_calls가 사용되지 않고 response의 content에 응답이 바로 내려온다.
---CALL AGENT---
---- agent에서 받은 response ----
content='한국의 수도는 서울입니다.' additional_kwargs={} response_metadata={'finish_reason': 'stop', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1'} id='run-d6822171-299f-4bae-92cb-4fbc606088a7-0'
Sync execution time: 0.769956334028393
"Output from node 'agent':"
'---'
{ 'messages': [ AIMessage(content='한국의 수도는 서울입니다.', additional_kwargs={}, response_metadata={'finish_reason': 'stop', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1'}, id='run-d6822171-299f-4bae-92cb-4fbc606088a7-0')]}
'\n---\n'


